Function Tracing
With Go, Lambda and X-Ray
When we build an app with many Lambda functions that use many AWS services, it can become a challenge to spot and diagnose errors.
Imagine if we see error from a worker API. How do we know if error was due to:
- AWS API Gateway internal error
- AWS Lambda capacity problem
- Our worker function panic
- Our worker function unhandled error
- Our worker function timing out
- AWS S3 permission error
We will naturally add more logging to our Go code over time to help understand execution. But Go on Lambda offers a new and compelling strategy for observability: tracing.
Tracing is a technique that big companies like Amazon, Google and Twitter rely on to understand their large-scale distributed systems.
With tracing, every request that comes in is given a unique request ID. Then care is taken to pass this request ID along to every subsystem that works on the request so they can report detailed, structured information about how they handled the request. This information is reported as “segments” of work – data with a start time, end time and other metadata like a function name, return value or error message.
One system might emit segments for many short function calls, then a single long RPC call. And the system that performs the RPC call itself might emit many segments for its function calls.
A centralized tracing service collects data from all the disparate systems and server and assembles them to provide a full picture of the life cycle of the request. We can now see total response time, individual steps and their duration, and in the case of a failure, pinpoint exactly where it happened.

Read more →
Static Sites
With S3, CloudFront and ACM
We often have static web content that we want to serve on the internet. This might be a standard HTML-based website for blogging. Or it might be part of a modern web app where we have a JavaScript-based React or Vue.js app that interacts with an API app.
In both cases there are many advantages to using S3 – AWS Simple Storage Service – for the static content.
When content is completely static, it is extremely reliable to store and cost-effective to deliver to users. Furthermore this simplifies our API app. Now it is only concerned with data, not content, making it easier to write and more cost-effective to run.
Compare this to a traditional Model View Controller (MVC) app approach like Rails or Django. In this architecture the API may spend lots of time rendering HTML, and the HTML may not get served to users if there is an application bug or a database outage.
Static websites are a solved problem on AWS. We simply create an S3 bucket configured for website hosting and upload the content with public-read permissions. Then anyone can access the content from a URL like http://www.mixable.net.s3-website-us-east-1.amazonaws.com with some of the highest reliability and lowest storage and bandwidth costs possible.
Serving this from a custom domain is also a solved problem. We add the CloudFront CDN, configured with an SSL cert via the AWS Certificate Manager, in front of the S3 bucket. When we point our DNS to CloudFront, users can access the content from a URL like https://www.mixable.net with some of the fastest delivery times and lowest bandwidth costs possible thanks to the global content caching network.
Let’s set this all up for our app…
Read more →
Worker Functions
With Lambda, CloudWatch Events, and S3
Lambda isn’t just for HTTP functions. Another application of a Go Lambda function is one that we will invoke manually or automatically to do some work. To accomplish this we need something to work against such as an S3 bucket, and the the Lambda Invoke API or CloudWatch Events to trigger our worker.
Read more →
HTTP Functions
With Lambda and API Gateway
An obvious application of a Go Lambda function is to handle an HTTP request. To accomplish this, we need the “serverless” API Gateway service to receive HTTP requests, translate that into an event, invoke our Lambda function, take it’s return value, and turn it into an HTTP response. There’s a lot of cool tech and options behind API Gateway service, but the promise of FaaS is that we don’t have to worry about it. So lets jump straight to our Go function.
Read more →
Intro to Go Functions-as-a-Service with Lambda
Why FaaS matters and why Go is well-suited for Lambda
Functions-as-a-Service (FaaS) are one of the latest advances in cloud Infrastructure-as-a-Service (IaaS). FaaS fits neatly under the “serverless” label – managed services that shield us users from any details about the underlying servers.
Serverless isn’t really new. S3 is one of the oldest cloud services, and has seen nearly universal adoption because us users can upload tons of data and let AWS worry about the computers, networks, hard drives and software required to never lose our data. S3 fits the definition of “serverless” to a tee. API Gateway and DynamoDB are other key serverless services.
But Lambda is farily new and does represent a shift in computing. Before Lambda, us users have been responsible for provisioning servers, instances or VMs to run our software. We have also been responsible for designing architectures that are resilient to instance failures, and that can scale instances horizontally and/or vertally as demand increases. Lambda promises to remove these worries. We upload a .zip file of our function to S3, and AWS manages all the infrastructure to run our function.
Lambda also represents a shift in programming to an event-driven architecture. Our code is no longer running on a server 24 / 7 listening for requests. Instead it lays dormant until AWS invokes it with an event. An obvious event is an HTTP request, delivered to our function by API Gateway. But AWS offers many other interesting event sources, like when a S3 bucket receives a new file, or a pre-configured schedule.
Read more →
Making Heroku Fast with the CloudFront CDN
A faster website results in a better experience and more engagement for your users.
In this experiment we see how easy it is to deploy Discourse, an open-source discussion platform written in Rails 5, to Heroku. We then see how easy it is to add the AWS CloudFront Content Delivery Network (CDN) via the Heroku “Edge” Add-on.
The result is a website that benchmarks 2 times faster with no changes to the app code.
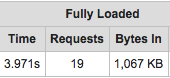 Before: 4 seconds
Before: 4 seconds
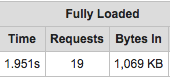 After: 2 seconds
After: 2 seconds
The CDN gives us this performance by instantly returning cached content over a single HTTP/2 connection, instead of making many requests to the Heroku dyno.
Read more →
BIOS - Simple GitHub Commit Statuses
You are invited to preview BIOS, a GitHub app that makes setting custom commit statuses easier and faster than ever.
Check out the BIOS GitHub app listing, install it for your org, add a bios.sh script to your repo, and enjoy fast automatic feedback on every code push to GitHub.
